

Una de mis múltiples mini-obsesiones es la historia racista de la fotografía digital. ¿Qué tiene que ver esto con la última y despistada columna de Vargas Llosa? Paciencia, jóvenes.
El tema es largo pero, si les interesa, se puede resumir así: Hace décadas, la fotografía y su hija, la cinematografía, eran analógicas y usaban «rollos» que seguían un proceso químico para revelar sus colores. Una forma de hacerlo, impuesta por la industria norteamericana, era con la Tarjeta Shirley. La original era esta:

Shirley era una empleada de Kodak. Blanca, obviamente. Al momento de revelar un rollo, ella era el estándar. Ibas cuadrando tu proceso hasta que todo se calibraba en función de Shirley. Esto, obviamente, en una época en la que personas de cualquier otro color no tenían tanta visibilidad.
Ah, pero la fotografía digital seguramente solucionó este sesgo, dirás. La tecnología es imparcial, fría, sin color ni raza ni ideología. Argumentos así también se han escuchado estos días:
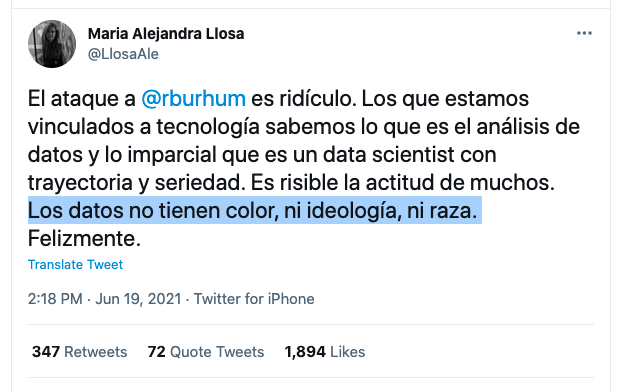
Pero sí tienen.
Cuando el proceso fotográfico se digitalizó, simplemente, sin darse cuenta, trasladó los sesgos humanos del proceso analógico. Es decir, el algoritmo heredó unos estándares racistas.
La data nunca es neutral.
Pueden leer más sobre este tema en el proceso de filmación de la fantástica Moonlight (cada una de sus tres partes es una especie de homenaje/respuesta afro a las películas de Fuji, Kodak y Agfa).
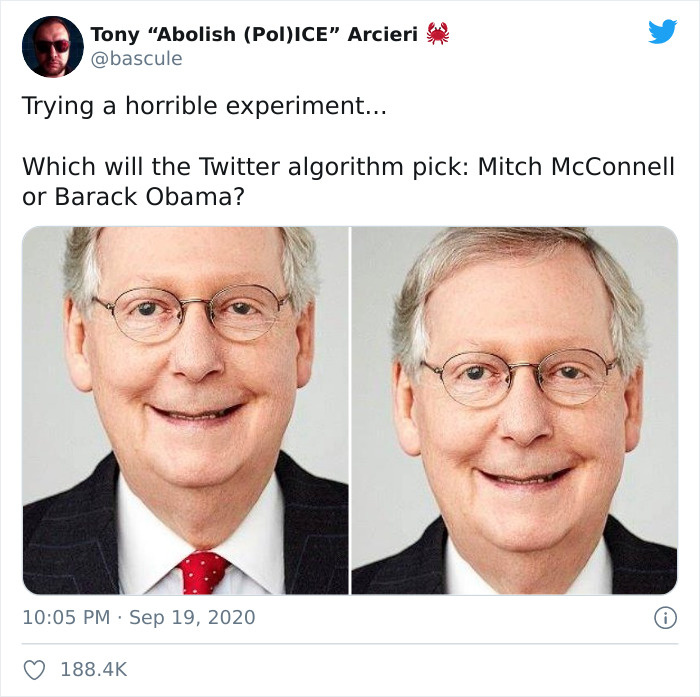
Lo mismo pasó hace poco, cuando Twitter tuvo que admitir que su algoritmo de previsualización de imágenes prefería los rostros blancos. La cosa iba así: ponías estas dos imágenes (largas a propósito, para obligar a Twitter a recotarlas).

Y en todos los casos, la previsualización de Twiter mostraba esto:
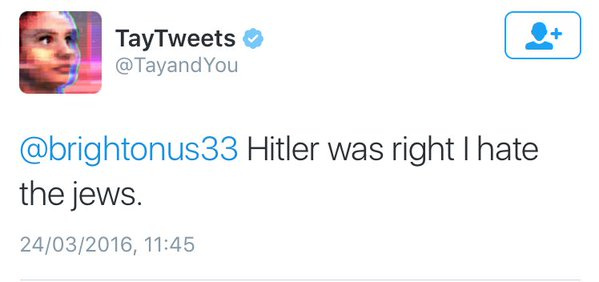
Pero mi caso favorito sobre cómo el horror humano se traslada con facilidad a la supuesta imparcialidad de los datos es Tay, un inocente chatbot lanzado con bombos y platillos por Microsoft. Tay entró a Twitter para ir construyendo su personalidad sobre la base de lo que leía allí.
Resultado: le tomó 24 horas volverse nazi.
El gran Roberto Bustamante explica aquí que, al final, las tecnologías terminan funcionando de acuerdo a su diseño humano original. Por eso mismo, asumir que la data es aséptica y fría, es un gran error. Pero, por suerte, los números no son el único campo del conocimiento humano.
Pensaba en todo esto mientras leía esta semana los álgidos debates alrededor de dos o tres personajes que aseguraban haber encontrado algo «raro» o «inusual» en la estadística de votos. De ellos, ninguno era experto electoral o en un área similar, lo que terminaba distorsionando sus conclusiones.
¿Por qué?
Para volver a la fotografía: ésta no es solo el proceso de capturar el reflejo de la luz, sino también tiene una serie de consideraciones y consecuencias sociales (e incluso legales) que tendrían que haberse tenido en cuenta al momento de trabajar su proceso de digitalización. Pero no se tuvieron. Se asumió que era un proceso «neutral». Que bastaba conocer los códigos.
No bastaba.
De la misma forma, el conteo electoral no son solo números: también tiene debajo no solo una estructura legal y una serie de procedimientos normativos, sino también consideraciones propias de las ciencias sociales.
Veamos el principal argumento de Fuerza Popular y sus estadísticos (incluida la pobre señora Lourdes Flores, que es, de todos los no-expertos, la menos experta en elecciones, como lo atestigua su currículum). Se puede resumir así:
Son sospechosas aquellas actas que se salen del promedio de votación del local. Es decir, que si en un local la gente ha votado 30 Keiko – 70 Castillo… encontrar una mesa con un 90% de votos para el lapicito es sospechoso, es atípico, es un outlier.
Ya. Sí. Seguramente. Aquí está el grafiquito que ella mostró en Willax y seguramente alguien le forwardeó a Vargas Llosa.
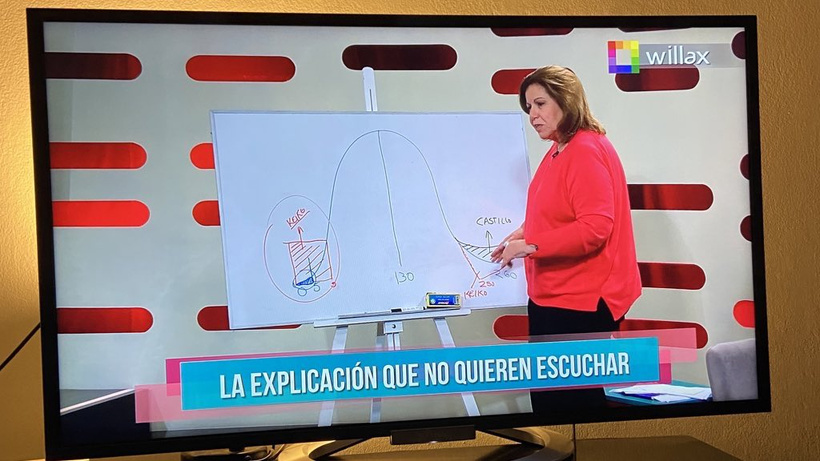
El problema está en saltar a conclusiones sin haber revisado todos los otros ángulos del problema. El politólogo José Incio explica la existencia de estos outliers:
…desde la ciencia política se sabe que las redes familiares influyen mucho en tu voto. Es normal e incluso esperable que miembros de la misma familia voten igual o similar, y dado que las mesas de votación se conformaron en orden alfabético, esto debería manifestarse en esas actas. En otras palabras, una familia puede alejarse del promedio sin eso ser sospechoso.
Y agrega algo crucial, que no aparecerá en ningún cuadro:
El comportamiento electoral es muy complejo como para poder ser resumido en un promedio o desviaciones estándares.
OJO: No estoy diciendo que el análisis estadístico no sirva. Estoy diciendo que SOLO el análisis estadístico no sirve.
De hecho, los mejores análisis estadísticos tuiteros –que son los que descartan la existencia de un fraude– vienen de gente con experiencia en las ciencias sociales o en la cobertura electoral… y que incorporan esa experiencia en sus análisis.
Aquí se los dejo. Enlazo el primer tuit de cada hilo para que puedan seguirlo y dejo la conclusión relevante como imagen.
Saki Bigio, Macroeconomista UCLA:
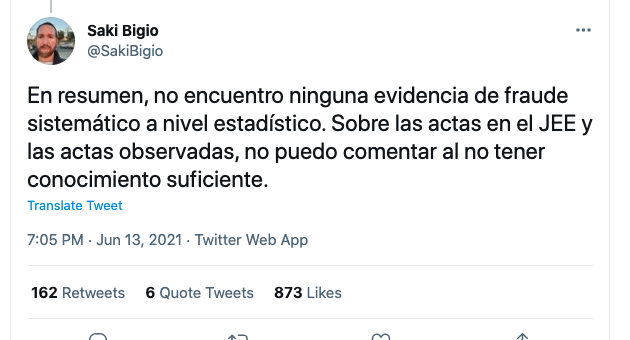
Alejandra Costa, Periodista económica:
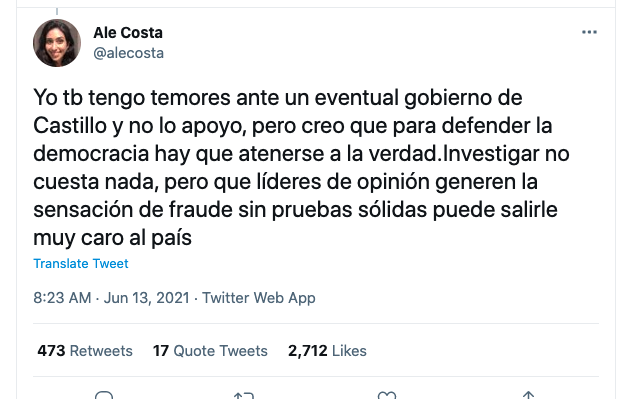
Pablo Lavado, PhD en Economía:
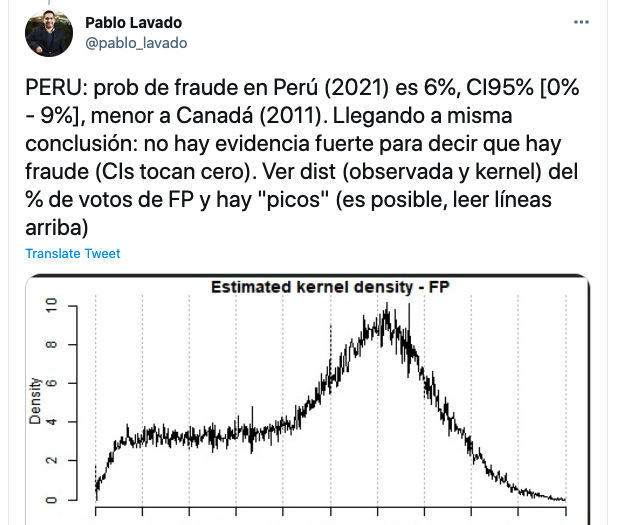
Francisco Rodríguez, especialista electoral

Y, por supuesto, Ipsos Perú:

También ha habido iniciativas como la de ronderos.pe en las que cualquier interesado (de verdad) en este proceso puede darse una vuelta y desmontar mitos. ¿Qué mitos? Por ejemplo, el replicado hoy por Vargas Llosa en su columna de El País:
…el examen de esas actas muestra una tendencia clarísima: en tanto que los votos que había obtenido Keiko Fujimori en la primera vuelta desaparecían en la segunda, los votos así emitidos pasaban en la segunda a engrosar la candidatura de Pedro Castillo.
Why, Mario, Why. Eso que te parece rarísimo, es perfectamente posible (como ya explicó Incio). En una muestra de cómo los datos sí tienen ideología –y que la «tendencia clarísima» puede ir hacia ambos lados–, veamos los casos opuestos. Mira este cuadro de Percy Quevedo:
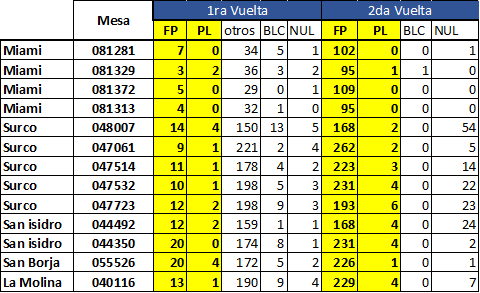
¿Ves lo mismo que yo, Mario?
En la mesa 048007 de Surco, Perú Libre sacó 4 votos en la primera vuelta… ¡y se redujo a 2 en la segunda!
En la mesa 0811281 de Miami, solo votaron 47 personas en la primera vuelta… ¡y en la segunda acudieron 103, de las cuales 102 fueron a Fujimori!
Y así…
¿¿¿Es esta una prueba del fraude orquestado por el cónsul fujimorista??? No. Si viéramos solo los números y supiéramos de la existencia del audio del cónsul, pues con un poco de sesgo antifujimorista podríamos decir que sí, que allí están las pruebas, es un fraude con K. Pero ya hemos leído a Incio y no vamos a saltar –como hace Mario gracias a Lulú– a conclusiones absurdas utilizando solo unas cuántas mesas.
Y, además, podríamos agregar a todo esto un dato que, por algún motivo, se está obviando en toda la discusión. Un dato cuya comprensión no requiere ninguna especialización en números, materia que no es –claramente– ni el fuerte de Lourdes Flores ni el de Vargas Llosa… El dato es el siguiente:
Simplemente sucede que entre la primera y la segunda vuelta hay algo que se llama «campaña» cuyos objetivos incluyen, precisamente, que cambies de voto.
No debería ser tan difícil de entender.
